
Некоторые владельцы сайтов пренебрегают реальной ролью Googlebot, пока не сталкиваются с проблемами, связанными с индексацией. В итоге, сайт с отличным дизайном, продуманной структурой и ценным контентом оказывается в тени поисковой выдачи. Это напрямую влияет на трафик и, как следствие, на доход. Речь идет не о «магии» SEO, а о детальной работе с тем, как Googlebot оценивает и сканирует страницы. Если это не настроено правильно, все усилия по разработке сайта оказываются неэффективными.
Ваш сайт может существовать годами – с красивым дизайном, продуманной структурой, экспертными текстами. И при этом оставаться в цифровой тени. Причина банальна: его либо не сканируют, либо сканируют не так, как нужно.
В центре этого процесса – Googlebot. Если понимать, как он принимает решения, как распределяет ресурсы и по каким сигналам отдает приоритет страницам, можно управлять индексацией. Если игнорировать – сайт превращается в склад контента без посетителей.
Я, бизнес-консультант Владимир Кривов, объясню, почему ваш сайт может быть идеальным на бумаге, но полностью невидимым для Google – и как с этим бороться.
Что такое Googlebot
Googlebot – это автоматизированная система сканирования поисковой системы Google. По сути, это программа, которая:
-
обнаруживает новые страницы,
-
переходит по ссылкам,
-
анализирует код,
-
фиксирует изменения,
-
передает данные в индекс поисковой системы.
После этого страница получает шанс появиться в поисковой выдаче.
Googlebot – не «робот» в бытовом понимании, а распределенная сеть краулеров. Они работают параллельно по всему миру, анализируя миллиарды URL. Их задача – поддерживать актуальную карту интернета.
Важно понимать: Googlebot не индексирует все подряд. Он выбирает, что сканировать, как часто возвращаться и сколько ресурсов выделять конкретному сайту.
Понимание важности SEO-продвижения с Googlebot приходит не сразу, но когда предприниматели сталкиваются с реальностью – сайт не работает на их бизнес, а трафик не конвертируется в продажи – они начинают искать профессионалов, которые способны сделать сайт «видимым» и конкурентоспособным.
SEO-компании вроде РОСТСАЙТ помогают выстроить грамотную стратегию, которая сразу начинает приносить результат.Здесь важна система, которая работает всегда и в любой экономической ситуации.
.png")
Два типа Googlebot: мобильный и десктопный
Сегодня Google применяет два основных пользовательских агента.
-
Googlebot Smartphone – имитирует поведение мобильного браузера.
Он лежит в основе mobile-first индексации. Это означает, что Google оценивает сайт так, как его видит пользователь смартфона. Версия для мобильных устройств стала отправной точкой ранжирования. -
Googlebot Desktop – воспроизводит работу настольного браузера.
Используется для сайтов, где анализ десктопной версии по-прежнему имеет значение.
Несмотря на различия в поведении, в файле robots.txt у них используется один и тот же токен продукта – Googlebot. Это означает:
-
вы не сможете задать разные правила для мобильного и десктопного краулера через robots.txt;
-
запрет или разрешение будет распространяться на оба варианта.
Эта деталь часто игнорируется, а затем владельцы сайтов удивляются, почему блокировка касается всего трафика от Google.
Как Googlebot распределяет ресурсы сканирования
Google не тратит бесконечные мощности на один сайт. У каждого домена есть свой «краулинговый бюджет» – условный объем ресурсов, который Googlebot готов использовать.
На распределение бюджета влияют:
-
скорость ответа сервера,
-
частота обновления контента,
-
структура внутренних ссылок,
-
наличие дублей,
-
общее качество сайта,
-
популярность и количество внешних ссылок.
Если сервер работает медленно или возвращает ошибки 5xx, Googlebot снижает активность. Если на сайте тысячи дублей и параметрических страниц – краулер расходует бюджет впустую.
Результат – важные страницы остаются вне индекса.
Что происходит во время сканирования
Процесс можно условно разделить на несколько этапов:
-
Обнаружение URL
Через ссылки, sitemap, редиректы, внешние упоминания. -
Запрос страницы
Googlebot отправляет HTTP-запрос, анализирует статус-код и загружает HTML. -
Рендеринг
Страница обрабатывается системой рендеринга, которая исполняет JavaScript. Это происходит не мгновенно – на тяжелых SPA-проектах возможны задержки. -
Анализ и индексирование
Извлекается текст, метаданные, структурированные данные, ссылки. После оценки качества страница может попасть в индекс.
Важно понимать: индексация не гарантируется. Google может просканировать страницу и решить, что она не заслуживает включения в базу.
.png")
Как управлять доступом Googlebot
Контроль сканирования возможен через несколько инструментов:
-
robots.txt – ограничивает доступ к разделам сайта;
-
метатег noindex – запрещает индексацию конкретной страницы;
-
HTTP-заголовок X-Robots-Tag – применяется к файлам (PDF, изображениям);
-
Google Search Console – позволяет отслеживать ошибки и статус индексации;
-
корректная структура внутренних ссылок.
Ошибки здесь обходятся дорого. Запретить важный раздел одним правилом в robots.txt – дело нескольких секунд. Восстановление индекса – месяцы.
Как оптимизировать сайт для сканирования
Чтобы Googlebot сосредоточился на ценном контенте, стоит работать по нескольким направлениям:
-
устранить дубли и параметрические URL;
-
настроить корректные канонические ссылки;
-
ускорить загрузку страниц;
-
регулярно обновлять контент;
-
поддерживать чистую структуру сайта;
-
отправить актуальный XML sitemap.
Googlebot реагирует на сигналы качества и структуры. Когда сайт логичен, быстр и регулярно обновляется, краулер возвращается чаще.
Почему это влияет на позиции
Индексация – фундамент поисковой видимости. Страница, которой нет в индексе, не участвует в ранжировании. Страница, просканированная редко, обновляется в поиске с задержкой. Страница, окруженная техническими ошибками, теряет потенциал.
Понимание логики Googlebot переводит SEO из области догадок в управляемый процесс.
Контроль сканирования – это контроль присутствия вашего бизнеса в поиске.
Mobile-first индексация: почему мобильный Googlebot стал главным
Сегодня поисковая система Google оценивает сайты через призму мобильной версии. Основной объем сканирования выполняет Googlebot Smartphone. Десктопный агент продолжает существовать, однако его роль вторична.
Это отражает реальность потребления контента: мобильный трафик во многих нишах стабильно превышает 60–70%. Поэтому при анализе страниц учитывается:
-
адаптивность верстки,
-
полнота контента на мобильной версии,
-
скорость загрузки на смартфонах,
-
корректность отображения интерактивных элементов.
Если мобильная версия урезана, скрывает текст или работает медленно, поисковая система фиксирует это как ограничение качества страницы.
.png")
С чего начинается работа Googlebot
Процесс сканирования стартует с огромной базы URL. В нее входят:
-
ранее проиндексированные страницы,
-
адреса из XML-карт сайта,
-
ссылки, обнаруженные на других ресурсах,
-
URL, добавленные через Google Search Console.
Эта база напоминает живую карту, которая постоянно обновляется. Каждый найденный URL – потенциальная точка следующего обхода.
Когда Googlebot заходит на сайт, он сначала обращается к уже известным страницам. Часто это:
-
главная,
-
разделы, указанные в sitemap,
-
страницы, которые недавно обновлялись.
Далее краулер проходит по внутренним ссылкам, выстраивая структуру сайта на основе связей между страницами. Чем логичнее перелинковка, тем проще системе понять архитектуру ресурса.
Логика приоритизации: Googlebot не действует хаотично
Сканирование не происходит случайным образом. У Google есть алгоритмы, которые определяют, какие страницы посетить раньше.
На частоту обхода влияют:
-
популярность URL,
-
наличие внешних ссылок,
-
регулярность обновлений,
-
историческая ценность страницы,
-
сигналы пользовательского интереса.
Если страница давно не обновлялась и не получает ссылок, она будет сканироваться реже. Если вокруг темы возникает всплеск поисковых запросов, Googlebot возвращается быстрее.
Robots.txt и технические ограничения
Файл robots.txt задает границы допустимого сканирования. Он сообщает, какие директории разрешены, а какие закрыты.
Однако контроль не ограничивается только этим файлом. На скорость обхода влияет производительность сервера. Если сайт отвечает медленно или возвращает ошибки 5xx, Googlebot снижает интенсивность запросов, чтобы не создавать дополнительную нагрузку.
Проблемы хостинга напрямую отражаются на частоте индексации.
Рендеринг JavaScript и динамический контент
Современный Googlebot способен выполнять JavaScript и отображать страницу почти так же, как браузер пользователя. Это позволяет индексировать:
-
одностраничные приложения (SPA),
-
контент, подгружаемый через AJAX,
-
интерактивные интерфейсы.
Однако процесс рендеринга требует дополнительных ресурсов. Если код перегружен, скрипты блокируют отображение или контент появляется только после пользовательского взаимодействия, индексация замедляется.
Для корректной обработки динамических сайтов важны:
-
серверный рендеринг или prerender,
-
доступность HTML-версии контента,
-
корректные статусы HTTP,
-
отсутствие блокировок в robots.txt для файлов JS и CSS.
Бюджет сканирования: скрытый лимит
Googlebot распределяет количество запросов к сайту за определенный период. Этот объем называют бюджетом сканирования.
На него влияют:
-
размер сайта,
-
скорость сервера,
-
структура ссылок,
-
количество дублей,
-
качество контента.
Если на ресурсе много технических ошибок или малозначимых страниц, робот расходует лимит впустую. В результате важные URL могут долго ждать повторного обхода.
Возникает замкнутая ситуация: плохая индексируемость снижает интерес робота, а редкие обходы замедляют рост видимости.
Динамика очереди сканирования
Очередь обхода постоянно пересматривается. На нее воздействуют:
-
появление новых внешних ссылок,
-
обновление текстов,
-
рост поискового спроса по теме,
-
активность пользователей.
Когда вокруг тематики усиливается интерес, Googlebot реагирует быстрее. Свежие ссылки с авторитетных сайтов также ускоряют повторный визит краулера.
Индексация – это непрерывный процесс пересмотра и оценки. Сайт, который регулярно обновляется и поддерживает техническую чистоту, получает более стабильное внимание поисковой системы.
Двойная идентичность Googlebot: как работает мобильный и настольный краулер
В процессе сканирования и индексации сайта Google использует два разных типа краулеров: один для мобильных устройств, другой для настольных компьютеров. Это двусторонний подход, который помогает оптимизировать сайт под новые реалии мобильной индексации, при этом сохраняя доступность информации для десктопных версий.
Как работает Googlebot: мобильный и десктопный краулеры
Сканирование и индексация в Google теперь в основном полагаются на Googlebot Smartphone. Этот краулер отражает новые приоритеты, определенные в рамках mobile-first индексации. В то же время Googlebot Desktop продолжает свою работу, но его роль ограничена дополнительным обходом тех страниц, которые либо недоступны в мобильной версии, либо не оптимизированы под мобильные устройства.
Двойная идентичность Googlebot означает, что для оптимизации нужно учитывать оба типа пользовательских агентов. Ожидается, что мобильная версия сайта будет обработана в первую очередь, а если она не соответствует стандартам, на помощь приходит десктопная версия.
После обновлений 2019 года оба типа Googlebot автоматические обновляются с использованием последних версий Chromium. Это позволяет улучшить работу с динамическими сайтами, учитывая потребности современных веб-ресурсов.
Строки пользовательских агентов: как отличить мобильную и десктопную версии
Каждый из краулеров идентифицирует себя с помощью уникальных строк пользовательских агентов, которые позволяют отличить мобильный Googlebot от десктопного:
-
Мобильная версия:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/WXYZ Mobile Safari/537.36 (compatible; Googlebot/2.1; +https://www.google.com/bot.html) -
Десктопная версия:
Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
Хотя на первый взгляд они схожи, существует важное различие: мобильная версия включает информацию о мобильной операционной системе, что помогает Googlebot понимать, как воспринимает страницу пользователь мобильного устройства. Для десктопной версии этого нет, что делает ее более универсальной для старых или неадаптированных страниц.
Проблемы с подделкой строк пользовательского агента
Однако использование этих строк не гарантирует, что за запросом стоит именно Googlebot. Злоумышленники могут легко подделать строки пользовательского агента, что приводит к рискам для сайтов, особенно для тех, кто сталкивается с «скрейперами» – автоматическими системами сбора данных.
Чтобы избежать обмана, Google рекомендует использовать проверку через обратный DNS-запрос. Это выглядит так:
-
Извлекается IP-адрес из логов сервера.
-
Выполняется обратный DNS-запрос для получения имени хоста.
-
Проверяется, заканчивается ли имя на googlebot.com или google.com.
-
Производится обратное разрешение имени хоста для подтверждения соответствия IP-адресу.
Этот процесс позволяет убедиться, что запросы действительно поступают от Googlebot, а не от мошеннических систем.
Индексирование с приоритетом мобильных устройств
Переход на индексацию с приоритетом мобильных устройств (mobile-first indexing) стал важной вехой в оптимизации сайтов. Ранее алгоритмы Google оценивали только десктопные версии страниц, а теперь основное внимание уделяется мобильной версии.
Почему это важно? Поисковая система использует мобильную версию сайта для принятия всех решений по индексации, даже если у вас есть отдельная версия для настольных ПК. Это означает, что сайт должен быть полностью адаптирован для мобильных пользователей, чтобы обеспечить лучшие позиции в поисковой выдаче.
Теперь, если сайт не предоставляет полноценную мобильную версию, Googlebot может оценить его по принципу «плохой мобильной оптимизации». Это напрямую повлияет на его видимость в поиске.
Почему мобильная оптимизация – это необходимость, а не опция
Google давно отдает приоритет мобильным версиям сайтов. Это уже не рекомендация, а обязательное требование, которое определяет, как ваш контент воспринимает поисковый робот. Если мобильная версия не соответствует стандартам, это напрямую влияет на видимость в поисковой выдаче, даже если ваш основной трафик поступает с десктопных устройств.
Когда Google использует десктопный Googlebot
Десктопная версия Googlebot активируется в нескольких случаях:
-
Когда мобильная версия значительно отличается от десктопной.
-
Когда мобильный контент сокращен или отсутствует.
-
Когда адаптивный дизайн не поддерживает корректное отображение иерархии контента.
Сайт, который не адаптирован для мобильных устройств, рискует потерять позиции в поисковой выдаче. Это также означает, что важный контент, плохая навигация или нестабильная загрузка элементов в мобильной версии не будут должным образом индексированы, даже если сайт выглядит хорошо на десктопе.
Если ваш сайт не оптимизирован для мобильных устройств, он рискует не попасть в топ поисковой выдачи. Это того, как Google воспринимает ваш ресурс в целом. И если мобильная версия не соответствует требованиям, это повлияет на всю стратегию SEO.
Роль Googlebot в индексации и ИИ
Googlebot, как традиционный веб-сканер, продолжает выполнять свою роль в поисковой системе, но с внедрением ИИ, таких как Gemini, ситуация меняется. Поисковая система использует большие языковые модели для создания ответов в диалоговом формате, но при этом базовая информация по-прежнему поступает от Googlebot.
Как Googlebot работает с поисковыми запросами с ИИ
Все данные, которые используются для ответов с помощью ИИ, проходят через стандартную инфраструктуру Googlebot, в том числе:
-
Сканирование – Googlebot ищет и индексирует веб-контент.
-
Индексирование – содержимое сохраняется в базе данных Google для дальнейшего анализа и использования.
-
Оценка с использованием ИИ – системы ИИ оценивают контент с точки зрения релевантности, доверия и понимания сущности, чтобы предоставить ответы.
Если ваш сайт не соответствует требованиям для сканирования и индексации, он не будет использоваться для генеративного поиска с ИИ, независимо от того, насколько он хорошо оптимизирован с точки зрения SEO.
Специализированные веб-краулеры Google
В дополнение к основному Googlebot, у поисковой системы есть специализированные краулеры, каждый из которых фокусируется на определенном типе контента:
-
Googlebot Image – для индексирования визуального контента.
-
Googlebot Video – для мультимедийных файлов.
-
Googlebot News – для получения актуальной информации для новостных поисков.
-
GoogleExtended – для обучающих данных, которые могут быть использованы для генеративного ИИ.
Эти специализированные краулеры оценивают контент по-разному и имеют свои собственные требования к индексации. Например, изображения требуют соответствующих тегов и метаданных, видео – корректного описания и транскрипции, а новостные статьи – актуальности и своевременности.
Если ваш контент оптимизирован лишь для стандартного веб-поиска, вы упускаете возможности для появления в других результатах поиска, таких как поиск изображений или новости. Правильная оптимизация для каждого из этих специализированных краулеров может значительно увеличить видимость вашего сайта.
Трехэтапный путь от сканирования до результата поиска
Процесс попадания вашего контента в результат поиска Google проходит три этапа: сканирование, индексирование и показ.
Этап 1: Сканирование
Googlebot начинает с обнаружения URL с помощью нескольких источников:
-
XML-карты сайта,
-
внутренние и внешние ссылки,
-
ранее просканированные страницы.
Когда сайт работает медленно или содержит постоянные ошибки, Googlebot снижает частоту сканирования. Это создает замкнутый круг: чем реже Googlebot сканирует, тем медленнее обнаруживаются обновления.
Этап 2: Индексирование
После сканирования Googlebot сохраняет контент в базе данных Google. Этот процесс включает в себя несколько уровней анализа:
-
Извлечение контента – анализ текста, изображений, видеоматериалов и других элементов.
-
Классификация – определение темы, языка и релевантности.
-
Оценка качества – проверка на оригинальность и полноту контента.
Технические проблемы, такие как дублированные страницы или ошибки в метатегах, могут снизить шансы на попадание страницы в индекс.
Этап 3: Отображение в результатах поиска
После успешного индексирования, контент подвергается оценке с использованием алгоритмов ранжирования. Google учитывает множество факторов, включая:
-
Качество контента,
-
Релевантность,
-
Показатели пользовательского опыта,
-
Сигналы EEAT (экспертность, авторитетность, доверие).
Ранжирование не зависит от того, что индексируется, а от того, как Google оценивает релевантность контента запросу пользователя.
Как часто Googlebot сканирует сайты
Частота сканирования зависит от нескольких факторов, таких как:
-
Авторитетность сайта,
-
Актуальность контента,
-
Производительность сервера,
-
Ценность контента для пользователей.
Новости или популярные ресурсы могут сканироваться несколько раз в день, в то время как менее активные сайты могут видеть робота раз в неделю или месяц.
Факторы, влияющие на частоту ползания Googlebot
Частота, с которой Googlebot сканирует ваш сайт, зависит от множества факторов, связанных как с техническим состоянием сайта, так и с его содержанием. Вот основные факторы, которые могут повлиять на активность краулера:
Ограничение скорости сканирования
Googlebot был спроектирован так, чтобы не перегружать серверы сайтов. Для этого в Googlebot встроена функция «ограничения скорости сканирования». Это означает, что Googlebot ограничивает количество запросов, которые он может отправить на сайт в единицу времени. Это позволяет поддерживать баланс между сканированием и нормальной работой сайта, избегая перегрузки.
Ограничения в Google Search Console
В Google Search Console вы можете настроить ограничение скорости сканирования, уменьшив количество запросов, которые Googlebot выполняет на вашем сайте. Однако увеличение лимитов не приведет к автоматическому увеличению частоты индексации. Это лишь позволяет сканировать больше страниц, если сервер способен выдерживать нагрузку.
Состояние сайта и производительность
Если ваш сайт быстро реагирует на запросы, Googlebot может увеличить количество одновременных подключений. Это означает, что робот может сканировать больше страниц. Если же сервер работает медленно или часто возникает ошибка, Googlebot будет ограничивать частоту сканирования, чтобы избежать дополнительной нагрузки.
Ошибки сервера
Частые ошибки сервера (например, 5xx ошибки) или таймауты соединения указывают на проблемы с сервером. В таком случае Googlebot снижает скорость сканирования, чтобы не перегружать сервер. Неполадки с сервером могут значительно снизить частоту сканирования, что, в свою очередь, затруднит индексацию контента.
Другие технические вопросы
На частоту сканирования также могут влиять:
-
Фасетная навигация и идентификаторы сессий – создают дополнительную нагрузку на сервер и могут привести к дублям страниц.
-
Дублированный контент – затрудняет определение уникальных страниц, снижая эффективность индексации.
-
Страницы с ошибками программного обеспечения или взломанные страницы – могут быть проигнорированы, что приводит к пропуску важного контента.
-
Бесконечные пространства и прокси-серверы – создают бесполезные циклы сканирования, замедляя работу Googlebot.
-
Низкое качество и спам-контент – может привести к тому, что такие страницы будут сканироваться реже.
Спрос на сканирование
Если Googlebot не видит большого спроса на определенный контент (например, страницы, на которые мало ссылок или которые редко посещаются пользователями), сканирование может происходить реже. Это может быть индикатором того, что страницы не воспринимаются как важные для индексации.
Популярность контента
Страницы, которые часто посещают пользователи или на которые ссылаются другие ресурсы, индексируются чаще. Googlebot считает такие страницы более актуальными, что повышает их приоритет для сканирования и индексации.
Устаревший контент
Google стремится избежать устаревания данных в индексе, поэтому старается обновлять старые страницы по мере появления нового контента. Если ваш сайт обновляется регулярно, Googlebot будет чаще его сканировать, чтобы обновить информацию.
События, затрагивающие весь сайт
Когда происходят значительные изменения на сайте, такие как изменение структуры URL, миграция на новый домен или изменение контента, это увеличивает активность сканирования. Googlebot ускоряет индексацию обновленного контента, чтобы поддерживать актуальность в поисковой выдаче.
FAQ: важные вопросы для онлайн-бизнеса о Googlebot. Как он влияет на вашу видимость и продажи
1. Как Googlebot влияет на результаты моего онлайн-бизнеса?
Googlebot определяет, какие страницы вашего сайта будут проиндексированы и, следовательно, видны в поисковой выдаче. Если страницы не индексируются правильно или сканируются с задержками, это приводит к снижению видимости вашего бизнеса в поиске и уменьшению трафика. Для онлайн-магазинов это может напрямую повлиять на количество потенциальных клиентов и выручку.
2. Как скорость сканирования Googlebot влияет на производительность моего сайта?
Googlebot сканирует страницы в рамках бюджета сканирования, который зависит от производительности сайта. Если сервер работает медленно или возникают ошибки, Googlebot будет тратить меньше ресурсов на ваш сайт. Это замедляет процесс индексации и задерживает появление новых товаров или обновлений в поисковой выдаче, что может негативно сказаться на своевременности продаж.
3. Какие технические проблемы могут препятствовать индексации важного контента?
Основные технические барьеры включают:
-
Ошибка 404 на страницах, которые должны быть доступны.
-
Медленное время отклика сервера (более 2 секунд), что влияет на частоту сканирования.
-
Блокировка ресурсов, таких как CSS или JavaScript, что затрудняет корректное отображение страниц и их индексацию.
-
Дублированный контент или неправильно настроенные канонические теги, которые приводят к путанице и потерям в позициях.
Эти проблемы могут уменьшить вероятность появления вашего сайта в результатах поиска и снизить его эффективность.
4. Как оптимизация мобильной версии сайта влияет на индексирование Googlebot?
С введением mobile-first индексации Googlebot сканирует и индексирует сайты, ориентируясь на их мобильную версию. Если мобильная версия не адаптирована должным образом или имеет ошибки, это может снизить позиции вашего сайта, несмотря на его хорошую оптимизацию для настольных ПК. Учитывая растущий мобильный трафик, отсутствие мобильной оптимизации приводит к потерям в поисковом трафике и продажах.
5. Какие параметры URL и динамические страницы могут уменьшить эффективность индексации?
Параметры URL, такие как идентификаторы сессий или фильтры сортировки, могут создать бесконечные циклы сканирования, что увеличивает расход бюджета сканирования и уменьшает приоритет индексации важных страниц. Особенно это актуально для интернет-магазинов, где параметры могут приводить к дублированию страниц. Использование канонических тегов и директив noindex помогает управлять этим процессом и сосредоточить индексацию на самых значимых страницах.
6. Как использование JavaScript влияет на сканирование Googlebot?
Googlebot улучшил свои возможности работы с JavaScript, но страницы, интенсивно использующие JavaScript, требуют больше вычислительных ресурсов для рендеринга. Это может замедлить процесс сканирования, а также привести к недоиндексации важных элементов, таких как кнопки для оформления заказов или динамически загружаемый контент. Чтобы избежать этого, рекомендуется использовать гибридные подходы с рендерингом на сервере для приоритетных данных и резервный HTML для улучшения индексации.
7. Как управлять доступом Googlebot к чувствительным или неважным страницам сайта?
Для управления доступом можно использовать несколько инструментов:
-
Файл Robots.txt для ограничения доступа к разделам сайта, которые не требуют индексации.
-
Метатеги robots для указания, какие страницы не следует индексировать (например, страницы с дублированным контентом или страницы оплаты).
-
Директивы HTTP-заголовков, такие как X-Robots-Tag, для настройки индексации для не-HTML-файлов, таких как PDF-документы.
Эти методы помогают оптимизировать использование бюджета сканирования и обеспечить, чтобы Googlebot сосредоточился на наиболее важном контенте.
8. Как часто Googlebot сканирует страницы моего сайта и что влияет на эту частоту?
Частота сканирования Googlebot зависит от нескольких факторов:
-
Скорости отклика сервера: если сервер медленно реагирует, Googlebot будет сканировать страницы реже.
-
Релевантности контента: страницы, которые часто обновляются или на которые ссылаются другие сайты, будут сканироваться чаще.
-
Ошибок на сайте: сайты с техническими проблемами (например, 404 ошибки) будут сканироваться реже, так как Googlebot будет избегать ненадежных страниц.
Для бизнес-сайтов важно поддерживать высокую производительность сервера и актуальность контента, чтобы обеспечивать регулярное и своевременное сканирование.
9. Как мне отслеживать, как часто Googlebot посещает мой сайт и какие страницы он индексирует?
Чтобы отслеживать активность Googlebot, можно использовать:
-
Отчет о статистике сканирования в Google Search Console, который покажет данные о частоте сканирования, объемах загруженных данных и времени отклика.
-
Анализ журналов сервера, где можно увидеть, какие страницы были посещены Googlebot, какие ошибки возникли, а также сколько времени заняло сканирование.
Эти данные помогут вам понять, какие страницы Googlebot пропускает или сканирует неэффективно, и исправить технические проблемы.
10. Что делать, если Googlebot не индексирует важные страницы?
Если Googlebot не индексирует важные страницы, проверьте:
-
Ошибки в кодах состояния, такие как 404 или 5xx.
-
Доступность ресурсов (CSS, JavaScript).
-
Канонические теги и метатеги noindex, которые могут ограничивать индексацию.
-
Реализовать корректные редиректы и проверить настройки Google Search Console для устранения блокировок.
Регулярный мониторинг этих аспектов поможет ускорить индексацию и повысить видимость вашего сайта в поисковой выдаче.
Как управлять доступом Googlebot
Управление доступом Googlebot к вашему контенту важно для оптимизации сканирования и защиты конфиденциальной информации. Для этого существуют различные инструменты и директивы.
Файлы Robots.txt
Файл robots.txt – это текстовый файл, который размещается в корневом каталоге сайта. Он информирует поисковых роботов о том, какие страницы или разделы сайта можно сканировать, а какие – нет. Например, директива Disallow: /admin/ запрещает сканирование административного раздела сайта.
Однако файл robots.txt является общедоступным, и его содержимое можно просматривать. Это важный момент, так как он не может быть использован для скрытия конфиденциальной информации. Кроме того, это всего лишь вежливая просьба, и не все роботы обязательно ее соблюдают.
Метатеги robots
Метатеги robots в HTML помогают управлять индексированием и сканированием страниц на уровне отдельных страниц. Например, директива noindex говорит поисковому роботу не индексировать страницу, но она все равно может быть проиндексирована, если на нее есть внешние ссылки.
Другие полезные директивы включают:
-
Nofollow – не следовать по ссылкам на странице.
-
Nosnippet – не показывать сниппеты в поисковой выдаче.
-
Noarchive – не показывать кэшированные версии страниц.
Комбинированные директивы могут выглядеть так: <meta name="robots" content="noindex, nofollow">.
Директивы HTTP-заголовков
Заголовки HTTP дают возможность контролировать индексацию на уровне серверных ответов. Например, X-Robots-Tag работает аналогично метатегам robots, но применяется к любым типам файлов (например, изображениям или PDF-документам). Этот способ особенно полезен для динамического контента.
Инструмент удаления URL в Google Search Console
С помощью инструмента Удаление URL в Google Search Console можно временно скрыть страницы из результатов поиска. Важно понимать, что это не влияет на индексирование – Googlebot все равно может посетить эти страницы, но они не будут отображаться в поисковой выдаче. Для долгосрочной блокировки нужно использовать другие методы, такие как настройка метатегов или удаление контента.
Как отслеживать активность Googlebot
Чтобы узнать, как часто Googlebot сканирует ваш сайт и какие страницы он посещает, используйте отчет о статистике сканирования в Google Search Console. Этот отчет покажет вам, сколько запросов было выполнено за последние 90 дней.
Для более подробного анализа используйте журналы сервера. Эти данные помогут понять, какие страницы Googlebot пропускает и как часто он сканирует страницы с низкой ценностью. Инструменты, такие как Screaming Frog или Splunk, могут помочь в анализе логов сервера, предоставляя подробную информацию о запросах Googlebot.
Проблемы с индексацией и их решение
Ошибки в индексации часто связаны с техническими проблемами на сайте. Например, ошибки 404, серверные ошибки или некорректные редиректы могут блокировать доступ Googlebot к контенту. Регулярный мониторинг с помощью Search Console и анализ логов сервера помогут вам выявить и устранить эти проблемы до того, как они повлияют на видимость сайта.
Обычные операции сканирования Googlebot: как избежать распространенных ошибок
1. Заблокированные ресурсы: CSS и JavaScript
Googlebot необходим доступ ко всем ресурсам, которые обеспечивают корректную работу страницы. Это включает и HTML-контент, и CSS-файлы, JavaScript-библиотеки и изображения. Если эти ресурсы заблокированы, Googlebot не сможет увидеть вашу страницу так, как ее видят пользователи, что значительно ухудшит индексацию и, как следствие, позиции в поисковой выдаче.
Что происходит при блокировке ресурсов:
-
CSS: Когда Googlebot не может загрузить стили страницы, он не видит, как работает адаптивный дизайн. Это в первую очередь влияет на индексацию с приоритетом мобильных устройств, что может понизить рейтинг вашего сайта в поиске.
-
JavaScript: Если файлы JavaScript заблокированы, Googlebot не сможет обрабатывать динамический контент, интерактивные элементы и сигналы о пользовательском опыте. Это особенно важно для сайтов, использующих современные фреймворки, такие как React или Vue, где взаимодействие с пользователем зависит от JavaScript.
2. Ошибки сканирования и коды состояния
Коды состояния HTTP играют первостепенную роль в том, как Googlebot интерпретирует доступность страниц. Неправильные или противоречивые коды могут привести к проблемам с индексацией.
Типичные ошибки:
-
Мягкие ошибки 404: Это страницы, которые возвращают код состояния 200, но содержат контент с пометкой «страница не найдена». Google заметит это, но такие ошибки тратят ресурсы и замедляют индексацию важных страниц.
-
Ошибка 404 на страницах, которые должны быть доступны: Это может происходить после миграции сайта или неправильной настройки перенаправлений, что приведет к тому, что Googlebot не сможет найти нужные страницы.
-
Цепочки перенаправлений: Когда на странице настроено несколько перенаправлений, каждое из которых увеличивает задержку, это ведет к излишней нагрузке на бюджет сканирования. Оптимально, чтобы количество перенаправлений не превышало пяти.
3. Проблемы с производительностью и временем отклика сервера
Медленная скорость отклика сервера значительно замедляет процесс сканирования и индексации, так как Googlebot не может эффективно загружать страницы. Результат – частые пропуски важных страниц или задержки с обновлением контента.
Идеальные параметры:
-
Время отклика сервера должно составлять менее 500 миллисекунд.
-
Время ответа более 2 секунд может снизить частоту сканирования для всего сайта.
Сайты, использующие интенсивные базы данных или плохо настроенные CDN, сталкиваются с дополнительными проблемами, так как Googlebot может получить некорректный контент в зависимости от географического расположения.
4. Проблемы с параметрами URL и бесконечные циклы сканирования
Параметры URL могут создать бесконечные циклы сканирования, что излишне расходует бюджет сканирования на страницы с малоценным или дублирующимся контентом.
Примеры таких параметров включают:
-
Идентификаторы сессий.
-
Параметры отслеживания.
-
Системы пагинации.
Сайты электронной коммерции особенно подвержены этому, так как фасетная навигация может порождать миллионы вариантов URL-адресов.
Решение:
-
Используйте канонические теги и метатеги noindex для указания Googlebot, какие страницы индексировать.
-
В Google Search Console можно настроить обработку параметров URL, чтобы направить краулер на каноничные версии страниц.
5. Проблемы с рендерингом JavaScript и динамическим контентом
JavaScript продолжает создавать проблемы для поисковых роботов, несмотря на улучшения в вычислительных мощностях Google. Рендеринг JavaScript требует значительных ресурсов и времени, что замедляет процесс сканирования.
Основные проблемы:
-
Контент, доступный только через JavaScript: Если важный контент загружается динамически с использованием AJAX или других технологий, Googlebot может не увидеть его.
-
Рендеринг на стороне клиента: Этот процесс требует значительных вычислительных ресурсов и может быть неполноценным.
-
Бесконечная прокрутка и отложенная загрузка: Если эти элементы реализованы некорректно, Googlebot может не «увидеть» весь контент, что приведет к пропуску важных данных.
Решение:
-
Используйте гибридные подходы, такие как рендеринг на стороне сервера для ключевых данных.
-
Поддержите JavaScript с резервным HTML и используйте структурированные данные для лучшей индексации динамического контента.
Оптимизация для Googlebot как конкурентное преимущество
Правильная настройка для поисковых роботов напрямую влияет на видимость сайта. Когда Googlebot может эффективно перемещаться по вашему сайту, новые страницы быстрее индексируются, обновления контента отображаются быстрее, а ценный контент не конкурирует с малозначительными страницами. Оптимизация для Googlebot должна быть важной частью общей стратегии SEO.
Пример оптимизации для Googlebot: как это влияет на бизнес
Оптимизация сайта для поисковых роботов, в частности для Googlebot, – это инвестиция, которая напрямую влияет на бизнес-показатели: скорость индексации страниц, количество видимых и доступных для пользователей страниц, а также эффективность поискового трафика, который может конвертироваться в продажи. Давайте рассмотрим, как различные аспекты оптимизации могут повлиять на экономику бизнеса и на эффективность использования бюджетов на SEO.
Влияние времени отклика сервера на бюджет сканирования
Предположим, что ваш сервер имеет время отклика выше 2 секунд. Это влияет на скорость сканирования сайта и увеличивает расход бюджета сканирования, что замедляет процесс индексации. Рассмотрим гипотетический пример для интернет-магазина, который продает товары на сумму 1 миллион рублей в месяц.
Сценарий 1: Время отклика меньше 500 мс
Время отклика сервера составляет 400 мс, что является оптимальным для сканирования. За день Googlebot сканирует 1000 страниц. Индексация происходит быстро, и новые товары появляются в поисковой выдаче почти сразу.
Сценарий 2: Время отклика больше 2 секунд
Время отклика сервера составляет 2500 мс, что является неэффективным для сканирования. Googlebot сканирует только 500 страниц в день. Это увеличивает время индексации, а новые товары появляются в поисковой выдаче гораздо позже.
Потери по трафику:
-
В Сценарии 1, за счет быстрого сканирования, сайт привлекает 1000 уникальных посетителей в день.
-
В Сценарии 2, из-за замедленного сканирования, сайт теряет 50% трафика.
Потери в трафике из-за низкой скорости отклика составляют:
1000 посетителей в день * 30 дней = 30,000 посетителей в месяц (Сценарий 1)
500 посетителей в день * 30 дней = 15,000 посетителей в месяц (Сценарий 2)
Бизнес теряет 15,000 потенциальных посетителей в месяц, что при среднем чеке в 2000 рублей на покупку дает:
15,000 * 2000 = 30,000,000 ₽ потерянного потенциала выручки в месяц.
Ускорение времени отклика сервера до 500 мс может привести к дополнительной выручке в размере до 30 млн рублей в месяц.
Влияние блокировки ресурсов (CSS, JavaScript) на индексацию
Если ресурсы CSS или JavaScript заблокированы для Googlebot, это может повлиять на корректную индексацию страниц. Рассмотрим два случая для онлайн-магазина, продающего технику:
Сценарий 1: Ресурсы CSS и JavaScript не заблокированы
В этом случае Googlebot может видеть все элементы страницы, включая адаптивный дизайн и динамические элементы. Это способствует правильной индексации и высокому ранжированию товаров, улучшая видимость магазина.
Сценарий 2: Ресурсы заблокированы
Если ресурсы, такие как стили CSS или файлы JavaScript, заблокированы, Googlebot не видит страницу в том виде, в котором ее видят пользователи. Это может привести к плохой индексации или даже к полному исключению страниц из поисковой выдачи.
Потери по трафику и выручке:
-
В Сценарии 1 сайт получает на 15% больше трафика, так как страницы индексируются корректно и хорошо ранжируются.
-
В Сценарии 2, из-за плохой индексации, трафик снижается на 20%.
Предположим, что магазин в обычное время получает 100,000 посетителей в месяц:
-
В Сценарии 1 – 100,000 посетителей.
-
В Сценарии 2 – 80,000 посетителей.
Потери в трафике: 100,000 - 80,000 = 20,000 потерянных посетителей в месяц. При среднем чеке 3000 рублей, потери составляют:
20,000 * 3000 = 60,000,000 ₽.
Вывод: Обеспечение доступа Googlebot ко всем необходимым ресурсам CSS и JavaScript может значительно повысить ваш трафик и потенциальную выручку.
Как решения по управлению параметрами URL влияют на индексируемость
Сайт, имеющий сложную систему параметров URL (например, параметры отслеживания сессий, фильтры сортировки или пагинацию), может столкнуться с проблемами дублирования контента и чрезмерного расходования бюджета сканирования.
Сценарий 1: Использование канонических тегов и инструментов Google Search Console
Если параметры URL обрабатываются через канонические теги или настройки в Google Search Console, Googlebot может эффективно сосредоточить свои усилия на индексации исключительно высокоценного контента.
Сценарий 2: Без использования канонических тегов
Если сайт не использует канонические теги или не обрабатывает параметры URL, Googlebot может тратить ресурсы на индексирование множества дублированных страниц.
Потери из-за неправильной индексации:
-
В Сценарии 1, когда дублированные страницы правильно обрабатываются, сайт индексирует 90% важных страниц.
-
В Сценарии 2, без правильной обработки, сайт индексирует всего 60% важных страниц.
Для магазина, который продает 1000 товаров в месяц, потерянный трафик будет следующим:
-
В Сценарии 1: 900 товаров индексируется.
-
В Сценарии 2: 600 товаров индексируется.
Предположим, что каждый товар приносит 10,000 ₽ выручки:
-
900 товаров * 10,000 ₽ = 9,000,000 ₽ (Сценарий 1)
-
600 товаров * 10,000 ₽ = 6,000,000 ₽ (Сценарий 2)
-
Потери: 9,000,000 ₽ - 6,000,000 ₽ = 3,000,000 ₽.
Вывод: Обработка параметров URL с помощью канонических тегов и инструментов в Google Search Console помогает избежать значительных потерь выручки и оптимизировать индексацию.
Экономическая выгода от правильной оптимизации для Googlebot
Внедрение правильных методов управления сканированием и индексацией улучшает видимость в поисковой выдаче и напрямую влияет на доходность бизнеса. Проблемы с производительностью серверов, заблокированные ресурсы или неправильная настройка параметров URL могут привести к потерям в трафике и выручке. Оптимизация этих факторов может приносить дополнительный доход в размере миллионов рублей ежемесячно.
Основные рекомендации:
-
Снижение времени отклика сервера до 500 мс.
-
Обеспечение доступа Googlebot ко всем критически важным ресурсам (CSS, JavaScript).
-
Правильная настройка канонических тегов и обработка параметров URL.
Эти шаги помогут улучшить индексируемость сайта, а также ускорить его рост в поисковой выдаче, что в свою очередь повысит трафик и прибыль.
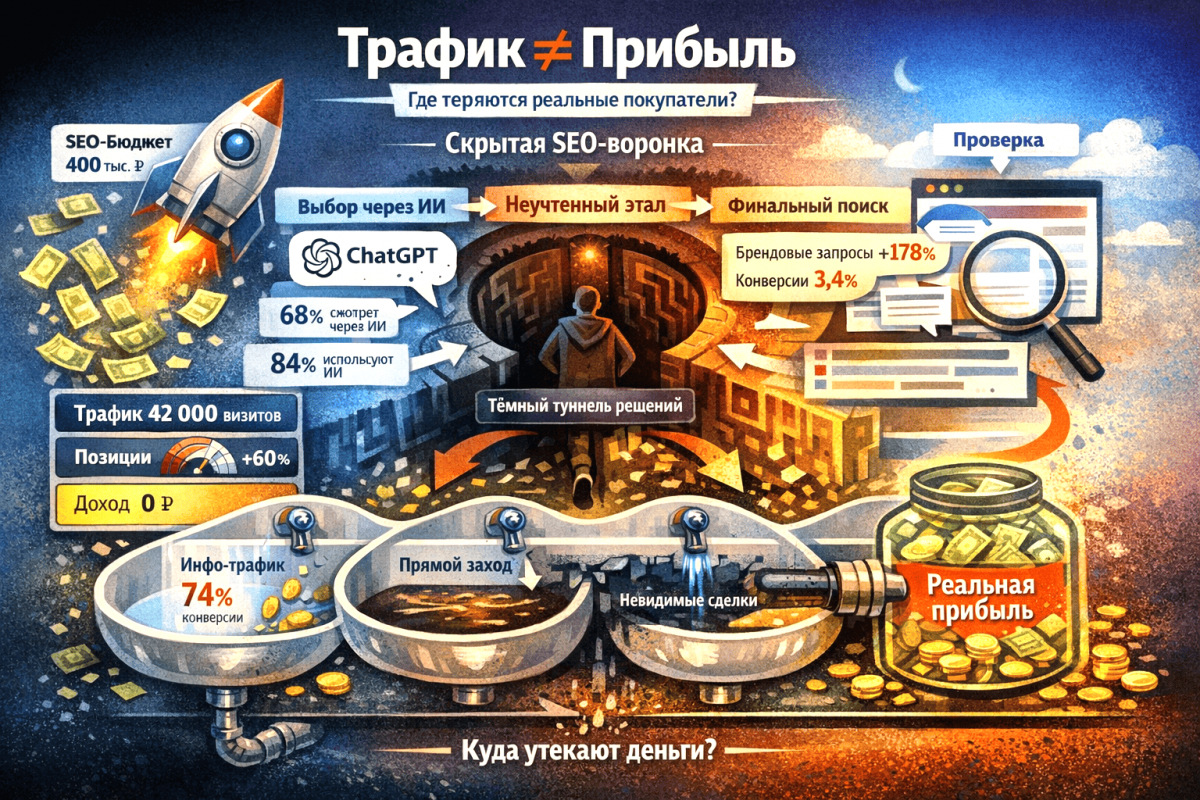
Предприниматели, которые считают, что сайт сам по себе принесет прибыль, сталкиваются с непреложной истиной: поисковые системы его просто не видят. Качественный контент и стильный дизайн не спасают, если не настроена правильная индексация. И вот тут начинается реальная проблема – все усилия по разработке теряются из-за того, что сайт не был подготовлен для сканирования Googlebot. В такие моменты становится понятно, что без профессионалов, как в SEO-компании РОСТСАЙТ, которые умеют управлять поисковыми алгоритмами, сайт так и останется в тени.
Иллюстрации созданы в РОСТСАЙТ



Комментарии